AI's "Triumph": Nvidia Says China Will Win, While AI Steals Your Articles
Alright, let's get this straight. Common Crawl, this supposed non-profit "library of the internet," is letting AI companies gorge themselves on copyrighted material, and then lying about it? Give me a break.
The Great Data Heist
They claim to scrape "freely available content," right? But The Company Quietly Funneling Paywalled Articles to AI Developers investigation drops a truth bomb: they're grabbing paywalled articles from major news outlets – The New York Times, The Wall Street Journal, The Atlantic itself – and feeding them to the AI training machine. OpenAI, Google, Nvidia, the whole damn gang. And when publishers ask them to stop, Common Crawl pretends to comply while doing jack squat.
Rich Skrenta, Common Crawl’s executive director, actually said, "You shouldn’t have put your content on the internet if you didn’t want it to be on the internet.” What kind of backwards logic is that? It's like saying if you leave your car unlocked, it's your fault when it gets stolen.
And the kicker? They're taking donations from the very AI companies they're enabling. Conflicts of interest, anyone?
It's all justified under the banner of "openness" and "robot rights." Skrenta even sent a letter to the Copyright Office with illustrations of robots reading books. Seriously? Last time I checked, robots don't have rights. Corporations do, and they're the ones making bank off this stolen content.
"Dusty Bookshelves," My Ass
Skrenta calls Common Crawl "just a bunch of dusty bookshelves." That's some seriously twisted PR spin. They're not passive archivists; they're actively helping AI companies build models that are designed to steal traffic and revenue from the very publishers they're scraping.

They could require attribution, as Stefan Baack suggests. A simple, cost-free solution that would help publishers track their content. But Skrenta dismissed it, saying it's not their responsibility. So, what is their responsibility? To be a free buffet for Silicon Valley giants?
And the search tool on their website? It's a joke. It claims there are "no captures" for domains like NYTimes.com, even when there are millions of articles in their archives. It's either incompetence or a deliberate attempt to mislead publishers. Maybe both. It's a mess, offcourse.
Oh, and get this: Skrenta wants to put Common Crawl's archive on a "crystal cube" on the moon, in case Earth blows up. He says The Atlantic won't be on that cube. Charming. It's like he's admitting that the work of journalists is disposable, while the data that fuels AI is sacred.
Who's Killing the Open Web?
Common Crawl and the AI industry love to talk about "openness." But let's be real: they're the ones killing the open web. By enabling rampant copyright infringement, they're forcing publishers to lock down their content even further, strengthening paywalls and making it harder for people to access information.
It ain't about "information wanting to be free." It's about corporations wanting to profit from other people's work without paying for it.
So, What's the Real Story?
It's a data heist disguised as digital preservation. Common Crawl is enabling the AI industry to steal content, undermine journalism, and consolidate power. And they're hiding behind a smokescreen of techno-libertarian rhetoric. Give me strength.

-

The Business of Plasma Donation: How the Process Works and Who the Key Players Are
Theterm"plasma"suffersfromas...
-
The Manyu Phenomenon: What Connects the Viral Crypto, the Tennis Star, and the Anime Legend
It’seasytodismisssportsasmer...
-
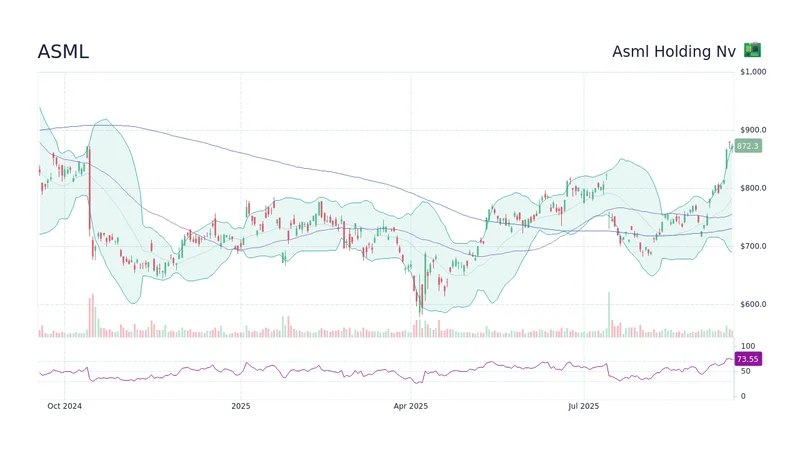
ASML's Future: The 2026 Vision and Why Its Next Breakthrough Changes Everything
ASMLIsn'tJustaStock,It'sthe...
-

The Nebius AI Breakthrough: Why This Changes Everything
It’snotoftenthatatypo—oratl...
-

The Great Up-Leveling: What's Happening Now and How We Step Up
Haveyoueverfeltlikeyou'redri...
- Search
- Recently Published
-
- Misleading Billions: The Truth About DeFi TVL - DeFi Reacts
- Secure Crypto: Unlock True Ownership - Reddit's HODL Guide
- Altcoin Season is "here.": What's *really* fueling the latest altcoin hype (and who benefits)?
- The Week's Pivotal Blockchain Moments: Unpacking the breakthroughs and their visionary future
- DeFi Token Performance Post-October Crash: What *actual* investors are doing and the brutal 2025 forecast
- Monad: A Deep Dive into its Potential and Price Trajectory – What Reddit is Saying
- MSTR Stock: Is This Bitcoin's Future on the Public Market?
- OpenAI News Today: Their 'Breakthroughs' vs. The Broken Reality
- Medicare 2026 Premium Surge: What We Know and Why It Matters
- Accenture: What it *really* is, its stock, and the AI game – What Reddit is Saying
- Tag list
-
- Blockchain (11)
- Decentralization (5)
- Smart Contracts (4)
- Cryptocurrency (26)
- DeFi (5)
- Bitcoin (30)
- Trump (5)
- Ethereum (8)
- Pudgy Penguins (5)
- NFT (5)
- Solana (5)
- cryptocurrency (6)
- XRP (3)
- Airdrop (3)
- MicroStrategy (3)
- Plasma (4)
- Zcash (7)
- Aster (10)
- qs stock (3)
- mstr stock (3)
- asts stock (3)
- investment advisor (4)
- morgan stanley (3)
- ChainOpera AI (4)
- federal reserve news today (4)