OpenAI, Meta & Anthropic's Next Moves: What the Data Reveals About Their Competing Visions
The release of a new large language model used to be a niche event, something for researchers and developers to dissect. Now, it’s a global headline. OpenAI’s launch of GPT-5 back in August was no exception, dominating news cycles with claims of a “significant leap in intelligence” and the tantalizing prospect of AI agents finally “joining the workforce.”
The initial data points are, on the surface, compelling. The model set new records across a slate of standardized tests: 94.6% on the AIME 2025 mathematics competition, 74.9% on the SWE-bench Verified coding assessment, and 84.2% on the MMMU multimodal understanding benchmark. These are impressive figures, and the reported reduction in the model’s tendency to "hallucinate" addresses a critical, long-standing flaw.
But as with any corporate filing or earnings report, the headline numbers rarely tell the whole story. The real analysis begins when you start to question the metrics themselves. The narrative OpenAI is selling is one of imminent, transformative economic impact. My analysis suggests the data supports a far more cautious conclusion. The gap between acing a standardized test and reliably performing a complex job remains a chasm, and we are being asked to leap across it on faith.
The Benchmark Mirage
Let’s be clear: the engineering achievement behind GPT-5 is not in dispute. Improving performance on these complex benchmarks is incredibly difficult. But we must scrutinize what these tests actually measure. They are, by definition, controlled environments. They test for peak performance on a narrow, well-defined problem set.
This is where I find the comparison to real-world work starts to break down. Scoring 94.6% on a math competition is a remarkable feat for a machine. It demonstrates powerful logical reasoning. But it is not the same as being a financial analyst, whose job involves navigating ambiguous data, dealing with incomplete information, and understanding the unwritten context behind a client’s request. The 5.4% of problems the model got wrong on that math test—what was the nature of those errors? Were they simple calculation mistakes or fundamental misunderstandings of the problem? In academia, a 95% is an A+. In finance, a 5% error rate can be catastrophic.
The same logic applies to coding. The model’s score was nearly 75%—to be more precise, 74.9% on SWE-bench. This indicates a strong ability to solve isolated programming challenges. But a corporate software engineer doesn't just solve puzzles. They navigate decades of legacy code, attend meetings to debate shifting product requirements, and make architectural decisions with long-term consequences. What happens when the AI agent fails on that remaining 25.1%? Who is liable for the bug it introduces into a critical system?

Thinking of these benchmarks as a proxy for job readiness is like judging a car’s suitability for a family road trip based solely on its 0-60 time. It’s a flashy, impressive number that tells you something about the engine's power, but it tells you nothing about its reliability, its safety features, its cargo space, or how it will perform in a snowstorm. We are being sold the 0-60 time and told to imagine the road trip.
From Calculation to Corporate Value
The most significant claim from OpenAI is not about benchmarks, but about economic integration. The suggestion that 2025 will see AI agents “materially change company output” is a specific, testable hypothesis, and a central part of the narrative around AI Breakthroughs: OpenAI, Meta & Anthropic’s Future for AI. This is the part of the report that I find genuinely puzzling, as it seems to willfully ignore the distinction between a powerful tool and an autonomous agent.
A tool, however advanced, is still wielded by a human. GPT-5 is an extraordinarily powerful tool for a coder, a writer, or a researcher. It can accelerate their work, handle tedious tasks, and provide a first draft. This will undoubtedly increase productivity. But an “agent” that “joins the workforce” implies a level of autonomy and reliability that simply isn't demonstrated by these metrics.
An agent must be trusted. It must be accountable. Its failure modes must be predictable and manageable. The reduction in hallucinations is a step in the right direction (though "reduced" is not the same as "eliminated"), but the core problem of reliability in open-ended, high-stakes environments remains. A human employee who makes a critical error faces consequences; they can be retrained or fired. What is the corporate governance framework for an AI agent that hallucinates a disastrous legal clause into a contract or a fatal flaw into a product design?
Details on how OpenAI plans to bridge this gap between statistical performance and enterprise-grade reliability are scarce. Until we see data on mean time between failures, on the cost and severity of those failures, and on the mechanisms for accountability, the "AI agent" remains a speculative product. The jump from a model that is correct most of the time to an agent you can trust with material business operations is not an incremental step. It’s a paradigm shift that no benchmark score can capture.
A High-Stakes Bet on Unproven Proxies
Ultimately, the narrative around GPT-5 conflates two very different things: performance in a sterile, academic environment and value creation in a messy, dynamic economy. The benchmarks are impressive, but they are proxies. And we are being asked to make a multi-trillion-dollar economic bet based on the hope that these proxies are telling us the truth about the future. The data, as it stands today, does not support that bet. It shows we have built a faster engine. It tells us nothing about the car it's been put into or the roads it will have to navigate.

-

The Business of Plasma Donation: How the Process Works and Who the Key Players Are
Theterm"plasma"suffersfromas...
-
The Manyu Phenomenon: What Connects the Viral Crypto, the Tennis Star, and the Anime Legend
It’seasytodismisssportsasmer...
-

The Nebius AI Breakthrough: Why This Changes Everything
It’snotoftenthatatypo—oratl...
-
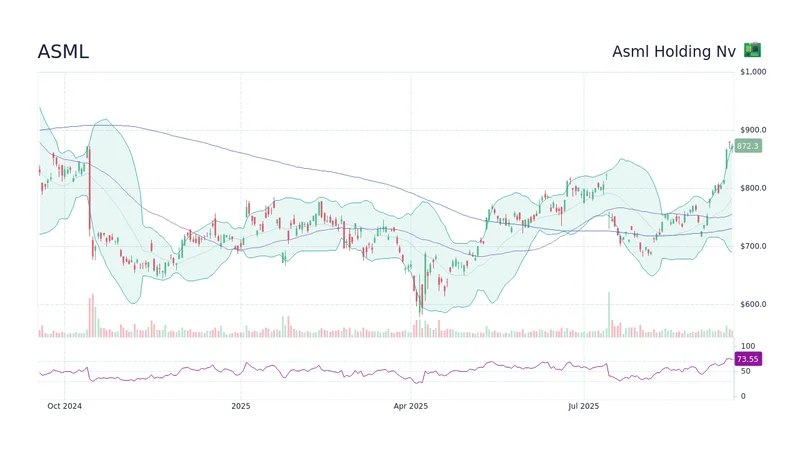
ASML's Future: The 2026 Vision and Why Its Next Breakthrough Changes Everything
ASMLIsn'tJustaStock,It'sthe...
-

The Great Up-Leveling: What's Happening Now and How We Step Up
Haveyoueverfeltlikeyou'redri...
- Search
- Recently Published
-
- Misleading Billions: The Truth About DeFi TVL - DeFi Reacts
- Secure Crypto: Unlock True Ownership - Reddit's HODL Guide
- Altcoin Season is "here.": What's *really* fueling the latest altcoin hype (and who benefits)?
- The Week's Pivotal Blockchain Moments: Unpacking the breakthroughs and their visionary future
- DeFi Token Performance Post-October Crash: What *actual* investors are doing and the brutal 2025 forecast
- Monad: A Deep Dive into its Potential and Price Trajectory – What Reddit is Saying
- MSTR Stock: Is This Bitcoin's Future on the Public Market?
- OpenAI News Today: Their 'Breakthroughs' vs. The Broken Reality
- Medicare 2026 Premium Surge: What We Know and Why It Matters
- Accenture: What it *really* is, its stock, and the AI game – What Reddit is Saying
- Tag list
-
- Blockchain (11)
- Decentralization (5)
- Smart Contracts (4)
- Cryptocurrency (26)
- DeFi (5)
- Bitcoin (30)
- Trump (5)
- Ethereum (8)
- Pudgy Penguins (5)
- NFT (5)
- Solana (5)
- cryptocurrency (6)
- XRP (3)
- Airdrop (3)
- MicroStrategy (3)
- Plasma (4)
- Zcash (7)
- Aster (10)
- qs stock (3)
- mstr stock (3)
- asts stock (3)
- investment advisor (4)
- morgan stanley (3)
- ChainOpera AI (4)
- federal reserve news today (4)